Bağlamdan Öğrenmenin Sınırları: Tencent CL-bench ile Gerçek Dünya Yetkinlikleri Test Ediliyor


yapay zeka alanında son yıllarda kaydedilen hızlı ilerlemelere rağmen, üst seviye modellerin gerçek dünya koşullarında hâlâ kırılgan olduğu görülüyor. Çinli teknoloji devi Tencent tarafından yayımlanan yeni bir teknik çalışma, yapay zekanın bağlamdan öğrenme konusunda önemli sınırlamalara sahip olduğunu ve bu durumun pratik kullanımı doğrudan etkilediğini vurguluyor. İnsanlar anında öğrenirken modellerin hatırlamaya çalıştığını gösteren örnekler, bu farkı somutlaştırıyor: bir yazılımcı daha önce görmediği bir araç için hızlıca dokümantasyonu tarayıp hata ayıklamaya başlar; bir oyuncu yeni bir oyunu kuralları okuyarak öğrenir; bir bilim insanı yüzlerce deney kaydını inceleyerek yeni ilişkiler keşfeder. Tencent’e göre insanlar, geçmişte ezberlenen sabit bilgilere bağlı kalmadan, karşılarına çıkan bağlama dayanarak öğrenmeyi sürdürürler.

Büyük dil modellerinin ise çoğu zaman önyargılı öğrenim süreçleriyla karşılaştığına dikkat çekiliyor. Ön eğitim sırasında parametrelerinde gömülü olan bilgiyi çağırır ve çıkış aşamasında yeni bilgiyi dinamik olarak öğrenmek yerine, statik iç belleğe yaslanır. Bu durum, çalışmada yapısal bir uyumsuzluk olarak adlandırılıyor; kullanıcılar sürekli değişen ve dağınık bağlamları çözebilien sistemler talep ederken, mevcut modeller bununla başa çıkmakta zorlanıyorlar.
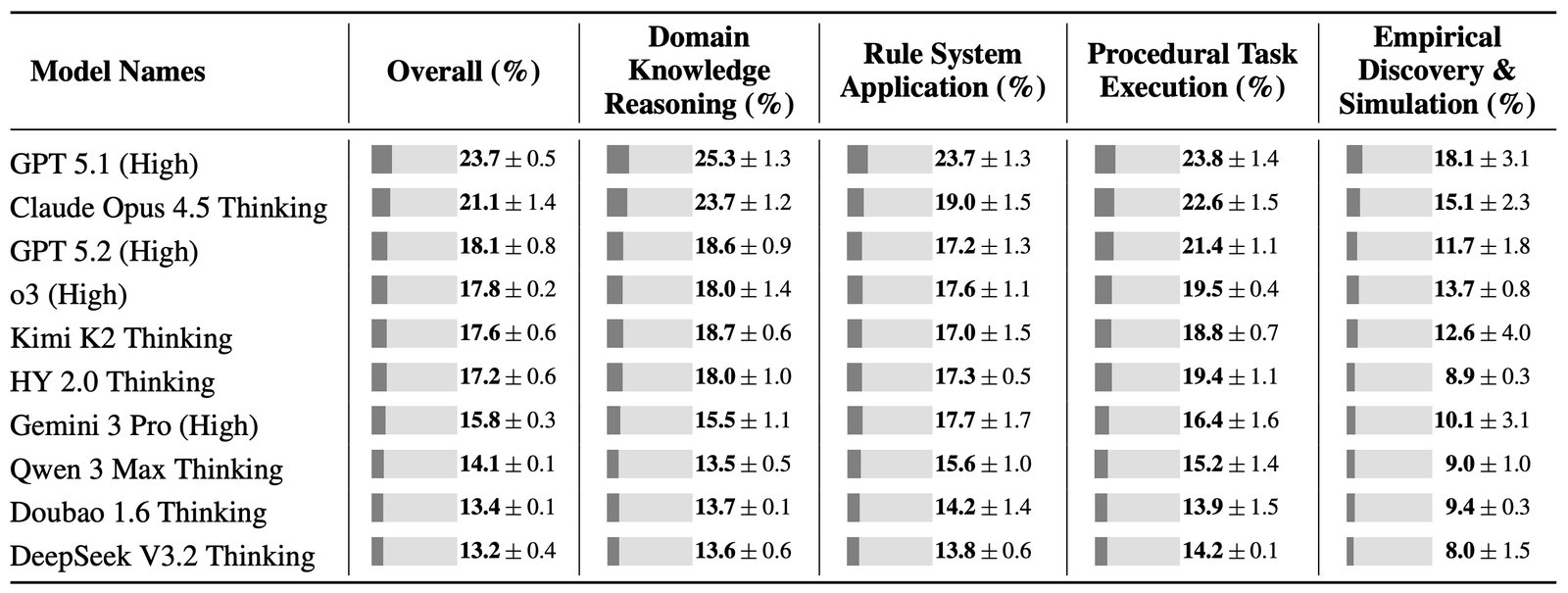
Bağlam öğrenmeyi ölçmek için yeni bir standart yaratıldı ve Tencent ekibi bu amaçla CL-bench adı verilen değerlendirme kriterini geliştirdi. 19 önde gelen yapay zeka modelinin, 500 farklı bağlam, 1.899 görev ve 31.607 doğrulama kriteri üzerinden test edildiği bu çalışma, modellerin iş başında öğrenme yeteneğini ve bağlamdan anlam çıkararak yeni durumlara uyum sağlayıp sağlayamadığını ölçüyor. Her görev, kendi bağlamını modele sunuyor; bu da insan öğrenme yaklaşımına daha yakın bir değerlendirme sunuyor. Ancak bir ayrım da dikkat çekiyor: sürekli öğrenme ile bağlam öğrenme birbirine karıştırılmamalı. Bağlam öğrenmede temel parametreler değişmeden kalırken, sürekli öğrenmede ağırlıklar güncellenir.
Ortalama başarı oranı sadece yüzde 17 olarak kaydedildi ve ilk 10 içerisindeki modellerin CL-bench üzerindeki ortalama sonuçları %17,2 civarında kaldı. En yüksek skor ise %23,7 ile OpenAI’in GPT-5.1 modeline ait olurken, onu %21,1 ile Anthropic’in Claude Opus 4.5 modeli takip ediyor. Çinli modeller arasında en iyi performans, Moonshot AI’ın Kimi K2 modelinde görüldü ve %17,6 seviyesinde yer aldı; Tencent’in kendi geliştirdiği Hunyuan 2.0 ise altıncı sırada ve %17,2 skoruyla kayda geçti. Bunlar, hâlâ bağlamı etkili biçimde kullanamayan modellerin çoğunlukta olduğunu gösteriyor. En başarılı olan GPT-5.1 bile bağlam verilmediğinde görevlerin yaklaşık %1’inden bile azını çözebiliyor.
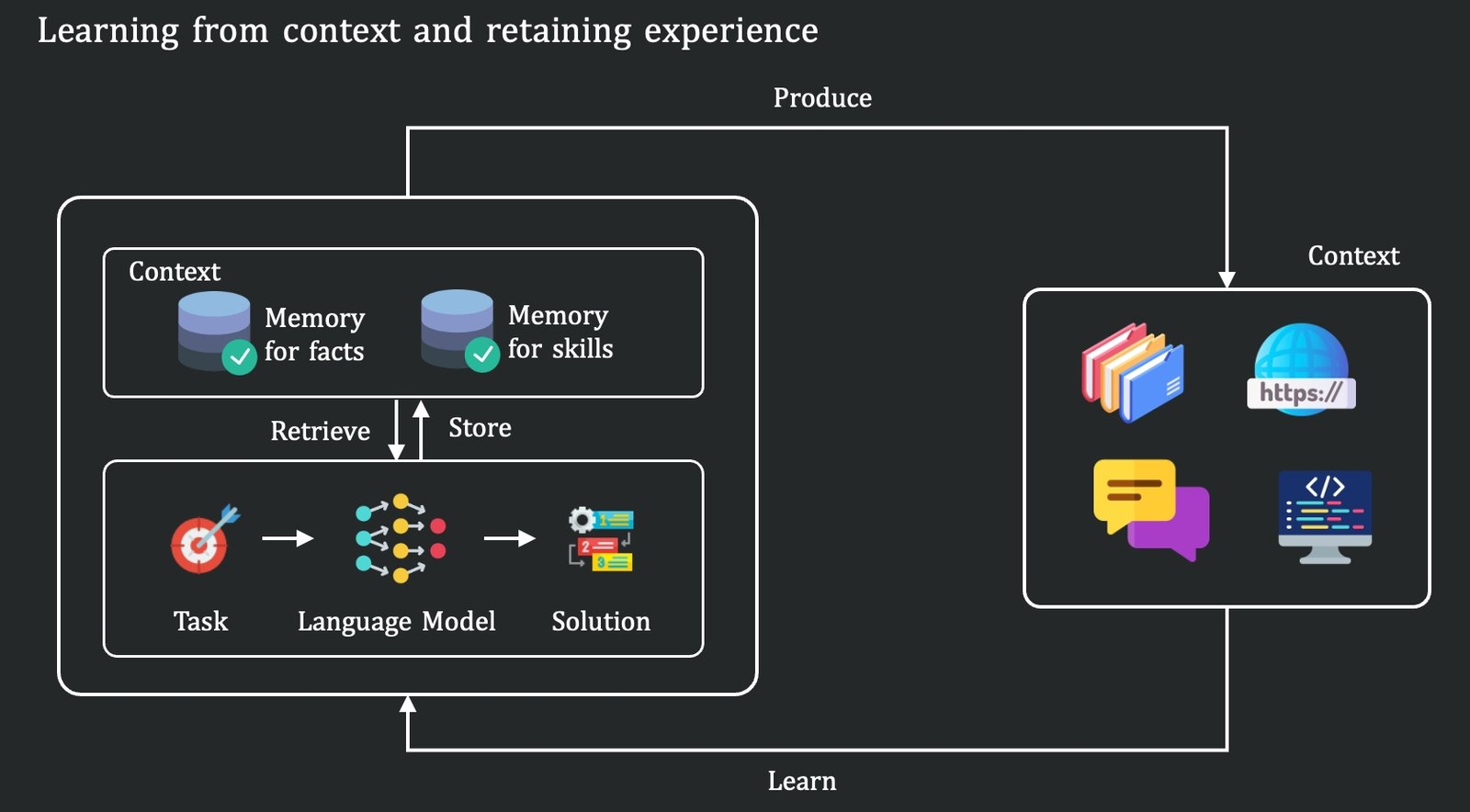
Çalışma, bağlam öğrenmenin ilerlemesiyle insan–yapay zeka ilişkisini yeniden tanımlayabileceğini öne sürüyor. Bu çerçevede insanlar, modele veri sağlayan aktörler olmaktan çıkarak, en uygun ve zengin bağlamı tasarlayan bağlam sağlayıcıları konumuna geçebilirler. Ancak Tencent’e göre bağlam öğrenme geçici bir süreç; bağlam penceresi kapandığında model öğrendiklerini unutuyor. Peki bu bilgi nasıl kalıcı hale getirilebilir? Bu sorunun yanıtı, yalnızca olguları değil, becerileri, deneyimi ve kalıpları da kapsayan daha derin bir öğrenme ihtiyacını gündeme getiriyor. Bu arada CL-Bench’e GitHub veya Hugging Face üzerinden ulaşabilirsiniz.