Deepseek OCR ile Uzun Belgeleri Görsel Formatta İşleyen Sistem: Verimlilik ve Kapasite Analizi


Çinli yapay zeka şirketi Deepseek, metin tabanlı belgeleri daha verimli analiz edebilmek amacıyla geliştirdiği yeni bir OCR (Optik Karakter Tanıma) teknolojisini tanıtıyor. Bu sistem, görsel tabanlı metinleri sıkıştırarak yapay zeka modellerinin uzun belgeleri belleğe takılmadan işlemesini mümkün kılıyor. Teknik rapora göre, içerikleri doğrudan metin olarak işlemeksiz, önce görüntü olarak ele alınıp analiz ediliyor; bu yaklaşım işlem yükünü önemli ölçüde azaltıyor. OCR çözümü, metinleri yaklaşık 10 kata kadar sıkıştırırken bilgilerin %97’sini koruyabildiğini gösteriyor.

Büyük dil modellerinin metni token’lara dönüştürmesiyle ilgili genel durumu hatırlatacak olursak, kısa kelimeler tek bir token ile temsil edilirken uzun kelimeler birden fazla token’a bölünebiliyor. Bu durum, bağlam penceresinin genişletilmesi için gerekli hesaplamaları artırsa da maliyetleri de yükseltiyor. Deepseek’in yaklaşımı ise içerikleri bir görsel olarak işlemek olduğundan, içerikler pikseller halinde işleniyor ve bu sayede uzun içeriklerde bile esneklik sağlanıyor.
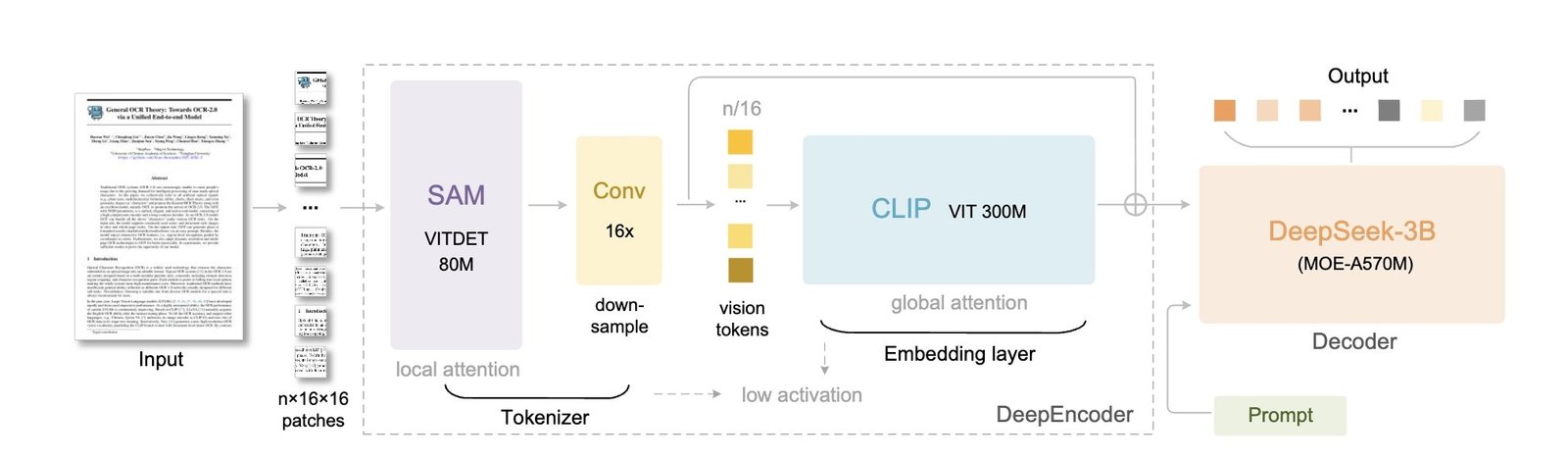
Sistemin temel bileşenleri iki ana başlık altında toplanıyor: DeepEncoder ve Deepseek3B-MoE. Görüntü işleme görevini yürüten DeepEncoder, 380 milyon parametreyle çalışıyor ve Meta’nın 80 milyon parametreli SAM ile OpenAI’nın 300 milyon parametreli CLIP modellerini bir araya getiriyor. Araya yerleştirilen 16x sıkıştırıcı, görüntü verilerini önemli ölçüde küçültüyor ve işlem hızını artırıyor. Örneğin, 1.024 x 1.024 piksel boyutundaki bir görselin 4.096 token’ı, sıkıştırıldıktan sonra yalnızca 256 token’a düşüyor. Sistemde kullanılan vizyon token sayısı, çözünürlüğe bağlı olarak 64 ile 400 arasında değişiyor ve bu, klasik OCR sistemlerin gerektirdiği binlerce tokenlik işlemleri önemli ölçüde hafifletiyor.
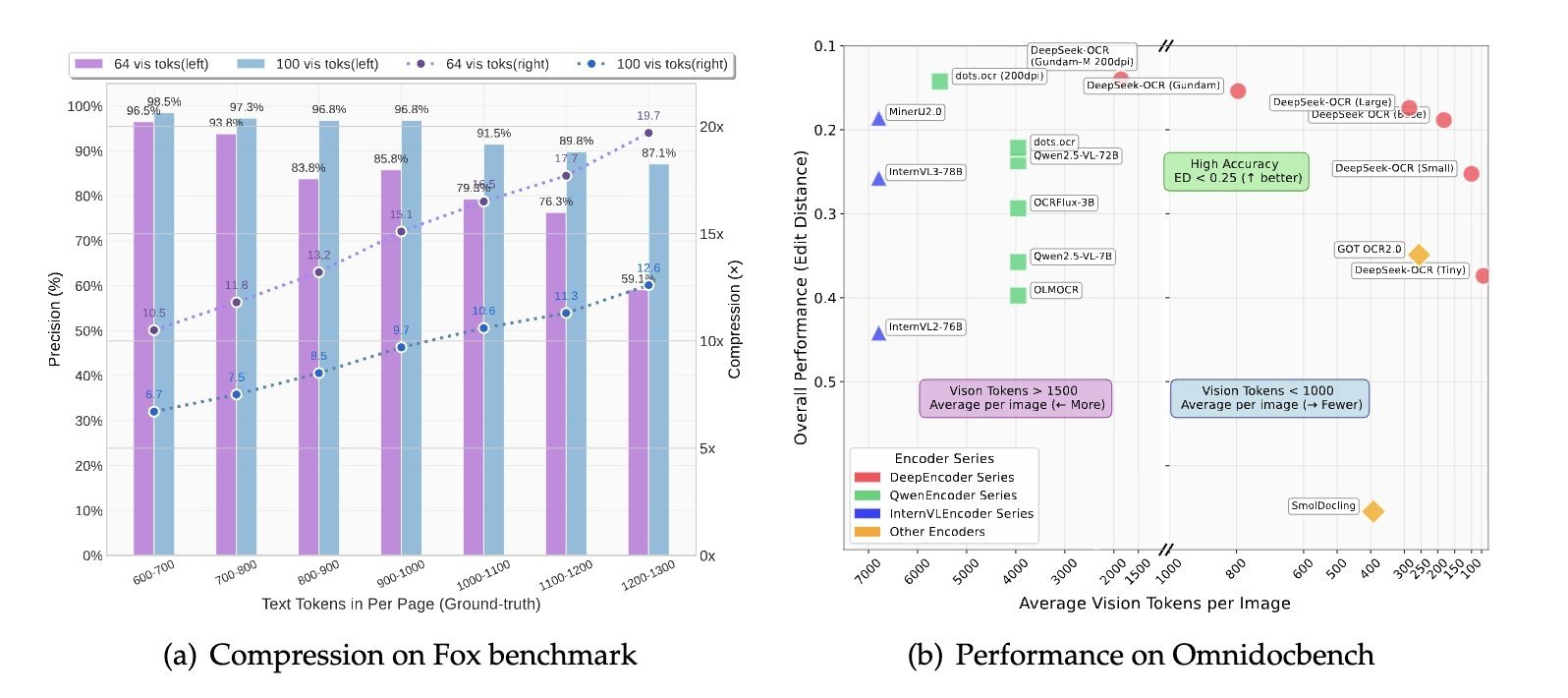
OmniDocBench testlerinde Deepseek OCR, sadece 100 vision token kullanarak GOT-OCR 2.0’ı geride bıraktı. Aynı zamanda 800 token’ın altında çalışırken MinerU 2.0’ın çok daha yüksek token gerektiren performansını da aştı. Farklı belge türleri için optimize edilen sistemde basit sunumlar için 64 token, kitap ve raporlar için 100 token, karmaşık gazeteler için ise “Gundam modu” adı verilen özel modla 800 token kullanılıyor. Ayrıca Deepseek OCR, diyagramlar, kimyasal formüller ve geometrik şekiller gibi görsel unsurları da işleyebiliyor ve yaklaşık 100 dilde çalışabiliyor. Biçimlendirmeyi koruyabiliyor; istenirse düz metin ya da genel görsel açıklaması üretebiliyor.
Günde 33 milyon sayfa işleme kapasitesine sahip olan sistemin eğitimi için yaklaşık 30 milyon PDF sayfası kullanıldı. Bunların 25 milyonu İngilizce ve Çince belgelerden oluşurken, geri kalanı 10 milyon sentetik diyagram, 5 milyon kimyasal formül ve 1 milyon geometrik şekli kapsıyor. Gerçek dünya kullanımında ise Deepseek OCR, tek bir Nvidia A100 GPU üzerinde günde 200.000 sayfadan fazla belgeyi işleyebiliyor. 20 sunucuda her biri sekiz A100 GPU taşıdığında toplam kapasite günde yaklaşık 33 milyona çıkıyor. Bu hız, yeni yapay zeka modellerinin eğitim verisi üretimini önemli ölçüde kolaylaştırma potansiyeli taşıyor. Ayrıca modelin hem kodu hem de ağırlıkları halka açık durumda sunuluyor.